📌 Accepted at Robotics Science and Systems (RSS), 2025
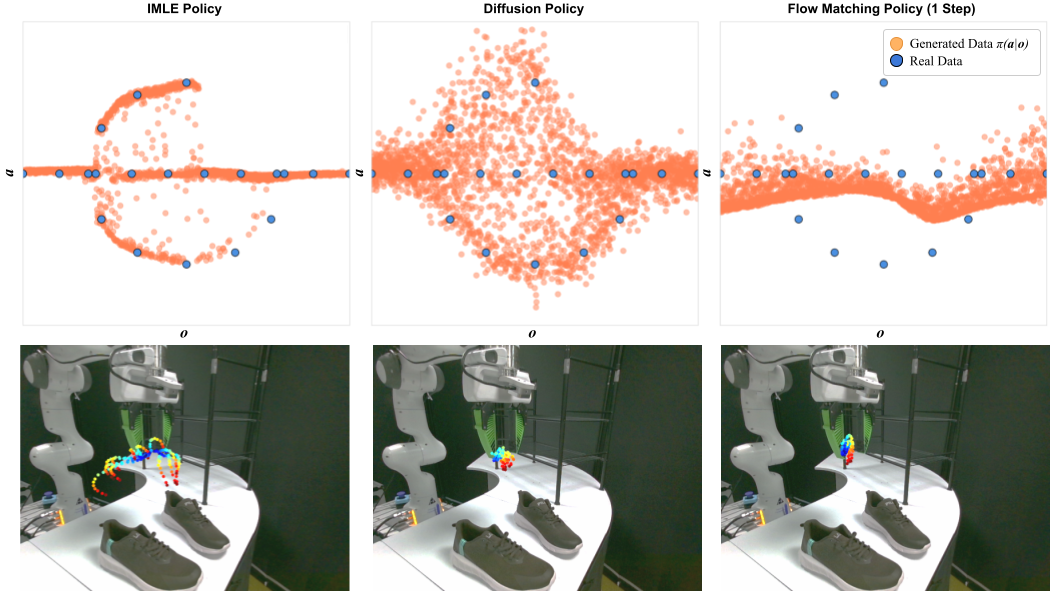
Recent advances in imitation learning, particularly using generative modelling techniques like diffusion, have enabled policies to capture complex multi-modal action distributions. However, these methods often require large datasets and multiple inference steps for action generation, posing challenges in robotics where the cost for data collection is high and computation resources are limited. To address this, we introduce IMLE Policy, a novel behaviour cloning approach based on Implicit Maximum Likelihood Estimation (IMLE). IMLE Policy excels in low-data regimes, effectively learning from minimal demonstrations and requiring 38% less data on average to match the performance of baseline methods in learning complex multi-modal behaviours. Its simple generator-based architecture enables single-step action generation, improving inference speed by 97.3% compared to Diffusion Policy, while outperforming single-step Flow Matching. We validate our approach across diverse manipulation tasks in simulated and real-world environments, showcasing its ability to capture complex behaviours under data constraints.
IMLE Policy Overview a) Training: The policy takes in a sequence of past observations 𝒪 and m sampled latents z for which the policy generates m sequences of predicted actions. Generated trajectories that lie within the rejection sampling threshold ε are rejected. From the remaining trajectories, the nearest-neighbour to the ground truth trajectory is selected for training. We minimise the distance between this trajectory and the ground truth trajectory to optimise the policy. As the loss focuses on each data sample, it ensures that all modes are captured even from small datasets. b) When compared to baselines with similar multi-modal capturing capabilities, IMLE can generate actions with a single inference step as opposed to multi-step de-noising processes. c) For highly multi-modal tasks, we enhance the performance of IMLE Policy by introducing a simple inference procedure to induce consistency upon mode choice based on a nearest-neighbour search over batch-generated action proposals with the previously executed action sequence.
@inproceedings{rana2025imle,
title = {IMLE Policy: Fast and Sample Efficient Visuomotor Policy Learning via Implicit Maximum Likelihood Estimation},
author = {Rana, Krishan and Lee, Robert and Pershouse, David and Suenderhauf, Niko},
booktitle = {Proceedings of Robotics: Science and Systems (RSS)},
year = {2025}
}